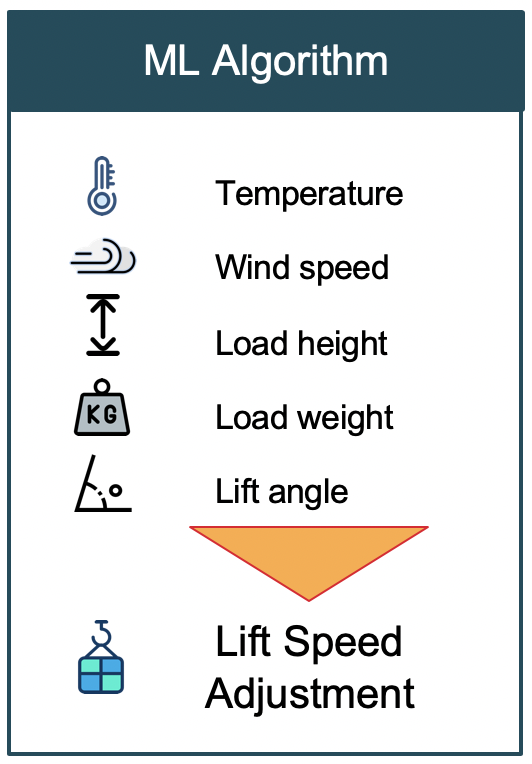
SOLID principles are design principles that help to create robust, scalable and maintainable software architecture. SOLID is an acronym which stands for:
- S – SRP (Single responsibility principle)
- O – OCP (Open closed principle)
- L – LSP (Liskov substitution principle)
- I – ISP ( Interface segregation principle)
- D – DIP ( Dependency inversion principle)
In the following sections I will describe all the principles by examples starting from one demo and upgrading this demo with the principles applyied.
- Reduce tight coupling
- Increase readability, extensibility and maintenance
- Achieve reduction in complexity of code
- Reduce error and implement Reusability
- Achieve Better testability of code
S – SRP (Single responsibility principle)
SRP principle says that every module/class should have only one responsibility and not multiply. Consider this class:
public class Customer
{
public void Register(string email, string password)
{
try
{
//code for registering user
if (ValidEmail(email))
{
SendEmail(email, "Email title", "Email body");
}
}
catch(Exception ex)
{
//log if error occurs
throw;
}
}
public bool ValidEmail(string email)
{
return email.Contains("@");
}
public void SendEmail(string mail, string emailTitle, string emailBody)
{
//send email
Console.WriteLine(string.Format("Mail:{0}, Title:{1}, Body:{2}", mail, emailTitle, emailBody));
}
}
Following this principle, the responsibility of the Customer class should be only the Register method. ValidEmail and SendEmail should not be defined in the same class. The Customer class should not worry with the definition of Validation Rules of the Email address and sending messages.
Following the SRP principle, the code should look like in the following way:
public class Customer
{
public void Register(string email, string password)
{
try
{
//code for registering user
var mailService = new MailService();
if (mailService.ValidEmail(email))
{
mailService.SendEmail(email, "Email Title", "Email Body");
}
}
catch (Exception ex)
{
//log if error occurs
throw;
}
}
}public class MailService
{
public bool ValidEmail(string email)
{
return email.Contains("@");
}
public void SendEmail(string mail, string emailTitle, string emailBody)
{
//send email
Console.WriteLine(string.Format("Mail:{0}, Title:{1}, Body:{2}", mail, emailTitle, emailBody));
}
}Now the functionality for Email Validation and Sending can be delegated to the MailService class.
O – OCP (Open closed principle)
OCP principle says that every module/class is open for extension and closed for modification. Consider the previous class with the SRP principle applied. Let’s say that we want to add additional functionality.After user registration and sending email we want to send sms to that user. According to the SRP principle we would add additional class for SMS as follows:
public class SmsService
{
public void SendSms(string number, string smsText)
{
//send sms
Console.WriteLine(string.Format("Number:{0}, Message:{1}", number, smsText));
}
}
After this the Customer class would be extended in the following way:
public class Customer
{
public void Register(string email, string password)
{
try
{
//code for user registration
var mailService = new MailService();
var smsService = new SmsService();
if (mailService.ValidEmail(email))
{
mailService.SendEmail("test@test.com", "User registration", "Body of message...");
}
smsService.SendSms("111 111 111", "User succesfully registered...");
}
catch (Exception ex)
{
//log if error occurs
throw;
}
}
}
As we saw we have extended the Customer class for sending different types of notifications which is against OCP rules. In order to follow the OCP principle and not the break the SRP principle we should isolate the sending of the notifications (email and sms) in a more generic way.
public abstract class NotificationService
{
public abstract void SendNotification();
}
public class MailService:NotificationService
{
public string Email { get; set; }
public string EmailTitle { get; set; }
public string EmailBody { get; set; }
public bool ValidEmail()
{
return Email.Contains("@");
}
public override void SendNotification()
{
//send email
Console.WriteLine(string.Format("Mail:{0}, Title:{1}, Body:{2}", Email, EmailTitle, EmailBody));
}
}
public class SmsService:NotificationService
{
public string Number { get; set; }
public string SmsText { get; set; }
public override void SendNotification()
{
//send sms
Console.WriteLine(string.Format("Number:{0}, Message:{1}", Number, SmsText));
}
}
public class Customer
{
public void Register(string email, string password)
{
try
{
//kod za registracija na korisnik
var mailService = new MailService();
mailService.Email = email;
mailService.EmailTitle = "User registration";
mailService.EmailBody = "Body of message...";
if (mailService.ValidEmail())
{
mailService.SendNotification();
}
var smsService = new SmsService();
smsService.Number = "111 111 111";
smsService.SmsText = "User succesfully registered...";
smsService.SendNotification();
}
catch (Exception ex)
{
//log if error occurs
throw;
}
}
}
As we can see we isolate the sending of email and sms as a component.
L – LSP (Liskov substitution principle)
LSP principle says that the parent object should easily replace the child object. Let me explain this principle by example. This principle is just an extension of the OCP and it means that we must ensure that new derived classes extend the base classes without changing their behavior. Consider the previous example with the SRP and OCP principles applied. Let’s say that we want to add additional functionality to the NotificationService class for writing notification records to Database but this records to be only for emails.
public abstract class NotificationService
{
public abstract void SendNotification();
public abstract void AddNotificationToDB();
}
public class MailService:NotificationService
{
public string Email { get; set; }
public string EmailTitle { get; set; }
public string EmailBody { get; set; }
public bool ValidEmail()
{
return Email.Contains("@");
}
public override void SendNotification()
{
//send email
Console.WriteLine(string.Format("Mail:{0}, Title:{1}, Body:{2}", Email, EmailTitle, EmailBody));
}
public override void AddNotificationToDB()
{
//add to database
}
}
public class SmsService:NotificationService
{
public string Number { get; set; }
public string SmsText { get; set; }
public override void SendNotification()
{
//send sms
Console.WriteLine(string.Format("Number:{0}, Message:{1}", Number, SmsText));
}
public override void AddNotificationToDB()
{
throw new Exception("Not allowed");
}
}
public class Customer
{
public void Register(string email, string password)
{
try
{
//kod za registracija na korisnik
var mailService = new MailService();
mailService.Email = email;
mailService.EmailTitle = "User registration";
mailService.EmailBody = "Body of message...";
if (mailService.ValidEmail())
{
mailService.SendNotification();
mailService.AddNotificationToDB();
}
var smsService = new SmsService();
smsService.Number = "111 111 111";
smsService.SmsText = "User succesfully registered...";
smsService.SendNotification();
smsService.AddNotificationToDB();
}
catch (Exception ex)
{
//log if error occurs
throw;
}
}
}
Above code in the Customer class will fail because of the AddNotificationToDB method in the smsService class called. One solution is not to call the above method but we raise another problem. We have a class that implements method that is not used. We will fix this issue if we implement in the following way:
public interface INotification
{
void SendNotification();
}
public interface INotificationToDB
{
void AddNotificationToDB();
}
public class MailService:INotification,INotificationToDB
{
//all the required code
}
public class SmsService: INotification
{
//all the required code
}
I – ISP ( Interface segregation principle)
The ISP says that clients should not be forced to implement interfaces they don’t use. According to the previous principles let’s say that we want to add additional functionality to the Notification interface for Reading notification from Database.
public interface INotificationToDB
{
void AddNotificationToDB();
void ReadNotification();
}
With this definition we obligate the class that inherits from this interface to implement the method for reading notification. Maybe in some cases we don’t want to have this but because of the inheritance we need to define the method in the class even if we don’t want to implement this. The solution for this problem is to separate all the methods that are not used everywhere in a separate interface like as follows:
public interface INotificationToDB
{
void AddNotificationToDB();
}
public interface INotificationToDBRead
{
void ReadNotification();
}
public interface INotification
{
void SendNotification();
}
public class MailService:INotification,INotificationToDB,INotificationToDBRead
{
//implemented code
}
public class SmsService: INotification
{
//implemented code
}
D – DIP ( Dependency inversion principle)
DIP says that high-level modules/classes should not depend upon low-level modules/classes. Both should depend upon abstractions. Secondly, abstractions should not depend upon details. Details should depend upon abstractions. Let’s explain this principle by example. From the previous principles we had the following situations with the Customer class:
public class Customer
{
public void Register(string email, string password)
{
try
{
//kod za registracija na korisnik
var mailService = new MailService();
mailService.Email = email;
mailService.EmailTitle = "User registration";
mailService.EmailBody = "Body of message...";
if (mailService.ValidEmail())
{
mailService.SendNotification();
mailService.AddNotificationToDB();
}
var smsService = new SmsService();
smsService.Number = "111 111 111";
smsService.SmsText = "User succesfully registered...";
smsService.SendNotification();
}
catch (Exception ex)
{
//log if error occurs
throw;
}
}
}
We have a lot of code here. Let’s isolate this class as a separate component.
public class Customer
{
private INotification notification;
public Customer(INotification n)
{
notification = n;
}
public void Register(string email, string password)
{
try
{
//kod za registracija na korisnik
}
catch (Exception ex)
{
//log if error occurs
throw;
}
}
public void SendNotification(INotification notification)
{
notification.SendNotification();
}
}
Having the architecture with all the principles applied we can call the Customer class from outside.
class Program
{
static void Main(string[] args)
{
var service = new MailService();
service.Email = "test@test.com";
service.EmailTitle = "User registration";
service.EmailBody = "Body of message...";
if (service.ValidEmail())
{
var customer = new Customer(service);
customer.Register("test@test.com", "password");
customer.SendNotification(service);
service.AddNotificationToDB();
}
var smsService = new SmsService();
smsService.Number = "111 111 111";
smsService.SmsText = "User succesfully registered...";
var customer1 = new Customer(smsService);
customer1.SendNotification(smsService);
Console.ReadLine();
}
}
As we saw, we have a total isolation and every functionality is represented as a component. Everything is abstracted, clear, easy for testing and most of all scalable, maintainable and usable.
Final remarks
We have gone throw all the principles for building scalable, maintainable and robust software architecture.
The code for implementing this principles is much longer than ordinary code but in long term you will have a big business value for the entire solution. You don’t have to follow all this principles 100% but it is a good practice if you want professional, easy readable and maintainable applications.